
Preventing Flaky Tests and Brittle Tests
Flaky tests and brittle tests are two common pitfalls that make our tests unreliable and hard to maintain. In this post, I will illustrate these concepts with examples and suggest ways to prevent such problems to ensure the reliability and maintainability of tests.
The examples provided in this post are written in Python, and pytest is used to validate them.
Flaky Tests
Flaky tests are those that exhibit nondeterministic outcomes (pass or fail) at each execution under the same conditions. This inconsistency can be due to various factors such as the use of random variables or external dependencies, or timing issues.
Using random variables
One of the most common causes of flakiness is probably the use of random variables.
Within the application
The following example uses a random variable within the application:
import random
class SortingHat:
def get_house(self, name: str) -> str:
houses = ["Gryffindor", "Hufflepuff", "Ravenclaw", "Slytherin"]
house = random.choice(houses)
print(f"The Sorting Hat has chosen {house} for {name}.")
return house
As you can see, the return value of get_house() is nondeterministic as it randomly selects and returns a house by using choice() method of random module.
A possible test case for this application would be written as follows:
def test_get_house():
sorting_hat = SortingHat()
house = sorting_hat.get_house("Harry Porter")
assert house == "Gryffindor"
This test is flaky because it relies on a random variable returned by the get_house method of the SortingHat class.
Consequently, it may pass sometimes if Gryffindor is chosen, but it could fail at other times if any other house is chosen.
In this scenario, the probability of the test failing is 75%, as there are four houses.
And the more the number of possible values, the higher the probability of failure accordingly, making the test even more unreliable.
To tackle this problem, you can use mocking or seeding.
The example below uses mocking:
import pytest
def test_get_house(monkeypatch: pytest.MonkeyPatch):
# Patch random.choice to always return "Gryffindor"
monkeypatch.setattr(random, "choice", lambda x: "Gryffindor")
sorting_hat = SortingHat()
house = sorting_hat.get_house("Harry Porter")
assert house == "Gryffindor"
By mocking, the get_house method only returns Gryffindor, ensuring predictable behavior during testing.
Or you can use seeding as follows:
import random
class SortingHat:
def get_house(self, name: str) -> str:
houses = ["Gryffindor", "Hufflepuff", "Ravenclaw", "Slytherin"]
# # Seed the random number generator to make the test deterministic
random.seed(name + "some salt to make it more random")
house = random.choice(houses)
print(f"The Sorting Hat has chosen {house} for {name}.")
return house
By seeding the random number generator with a consistent value based on input parameters, you can ensure that the test consistently produces the same results across different test runs.
The choice between mocking and seeding depends on factors such as the complexity of your code and the requirements of your applications. While mocking can provide determinism without altering the application code, it may lead to a disconnect between the test and the actual behavior of the system. On the other hand, seeding the random number generator aligns the test with the real behavior of the system but requires modifying the application code.
Meanwhile, what’s more challenging to track down is the cause of tests that are relatively more reliable yet still flaky. Let’s see what this means with another example with a different context.
Within the test
This time, random variables are used in the test, not in the application under test.
Here we have the create_user function, which creates and returns an instance of the User class:
class User:
def __init__(self, name: str, id: int):
self.name = name
self.id = id
def create_user(name: str, id: int) -> User:
if not 0 < id:
raise ValueError("id must be positive")
user = User(name, id)
return user
Let’s say a developer writes a test case to verify if create_user indeed creates a User with the id passed into it:
def test_create_user():
name = "Mickey"
id = random.randint(0, 99)
user = create_user(name, id)
assert user.name == name
assert user.id == id
In this scenario, the test’s failure probability is 1%, given that there are 100 potential values generated by random.randint(0, 99).
Only one of these values, namely 0, would result in a failed test.
Consequently, there’s a high likelihood that the test will pass, creating a false belief in its reliability.
By the time the failure occurs, it might not be immediately reproducible, making it more challenging to isolate and fix the underlying issue.
To prevent this problem, you can consider using deterministic values for testing instead of relying on random variables.
In this case, you could replace the random ID generation with a fixed value or a controlled set of values that cover relevant test cases.
This approach ensures that the test consistently evaluates the behavior of the create_user function without introducing unnecessary flakiness from random inputs.
External dependencies
Relying on external dependencies that beyond our control can lead to test flakiness.
Here is a simple example that depends on external dependencies:
import requests
def get_response(url: str) -> requests.Response:
return requests.get(url, timeout=1)
And one can write a test case for this as follows:
def test_get_response():
url = "https://example.com/"
response = get_response(url)
assert response.status_code == 200
This test could become flaky if the response time exceeds 1 second or the external service (https://example.com/) is down temporarily.
Or it could be the unreliable network that can cause the flakiness.
The most general approach to prevent such issue in this case is using mocks as follows:
def test_get_response(monkeypatch: pytest.MonkeyPatch):
url = "https://example.com/"
# Define a mock response object
class MockResponse:
def __init__(self, status_code):
self.status_code = status_code
# Define a mock function to replace requests.get()
def mock_get(*args, **kwargs):
# Simulate the behavior of the external service
return MockResponse(200)
# Use monkeypatch to replace requests.get() with the mock function
monkeypatch.setattr(requests, "get", mock_get)
# Call the function under test
response = get_response(url)
assert response.status_code == 200
In this test, pytest.MonkeyPatch is used to replace the requests.get() function with a mock function (mock_get).
This mock function simulates the behavior of the external service by returning a mock response with 200 status code.
As a result, you can isolate the code under test from its dependencies and ensure that the test remains reliable regardless of external factors.
Timing issues: Concurrency
Concurrency is also a possible cause of flakiness. Flakiness due to concurrency is subtler and more difficult to track down than other causes of flakiness.
Let’s see how it leads to nondeterministic test results and some ways to prevent them.
Within the application
The application code with concurrency may lead to flakiness in test outcomes.
Let’s say we have a function named get_factorials, which get the factorial values of the given numbers concurrently using multiple threads as follows:
import concurrent.futures
from math import factorial
def get_factorial(url: str) -> int:
return factorial(url)
def get_factorials(nums: list[int]) -> list[int]:
"""
Get factorials of the given numbers concurrently using multiple threads.
"""
results = []
# Create a ThreadPoolExecutor with the desired number of threads
with concurrent.futures.ThreadPoolExecutor(max_workers=len(nums)) as executor:
# Submit tasks to the executor
futures = [executor.submit(get_factorial, num) for num in nums]
# Wait for all tasks to complete and collect the results
for future in concurrent.futures.as_completed(futures):
result = future.result()
results.append(result)
return results
And we have the following test case for get_factorials:
def test_get_factorials():
nums = [1, 2, 3]
status_codes = get_factorials(nums)
assert status_codes == [1, 2, 6]
This test is flaky in that get_factorials does not guarantee the order of results.
This is because the execution of threads can be nondeterministic, meaning that the order in which the threads complete their tasks may vary over time.
For this particular example, you may simply sort the outcomes of the result to prevent flakiness in the test:
def test_get_factorials():
nums = [1, 2, 3]
status_codes = get_factorials(nums)
assert sorted(status_codes) == [1, 2, 6]
Some other ways to deal with this problem is to consider implementing strategies such as deterministic thread scheduling, or having an option of limiting concurrency to reduce the likelihood of flaky test outcomes as follows.
Below is an example that allows an option to limit concurrency:
def get_factorials(nums: list[int], max_workers: int = 4) -> list[int]:
"""
Get factorials of the given numbers concurrently using multiple threads.
"""
results = []
# Create a ThreadPoolExecutor with the desired number of threads
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
# Submit tasks to the executor
futures = [executor.submit(get_factorial, num) for num in nums]
# Wait for all tasks to complete and collect the results
for future in concurrent.futures.as_completed(futures):
result = future.result()
results.append(result)
return results
def test_get_factorials():
nums = [1, 2, 3]
status_codes = get_factorials(nums, max_workers=1) # Use only 1 thread
assert status_codes == [1, 2, 6]
This way, the test becomes deterministic as it deploys only one thread to limit concurrency.
Within the test
Tests can become flaky if you use shared resources between multiple tests and run them concurrently without proper synchronization.
Look at the following code:
# product.py
from redis import Redis
redis = Redis()
class Product:
def __init__(self, id):
self.id = id
@property
def quantity(self):
return int(redis.get(f"product:{self.id}:quantity") or 0)
@quantity.setter
def quantity(self, value):
redis.set(f"product:{self.id}:quantity", value)
def add_quantity(self, value):
self.quantity += value
def reduce_quantity(self, value):
self.quantity -= value
def reset_quantity(self):
self.quantity = 0
In the example above, we have Product class that uses Redis to store and manage quantity information for each product.
It also has three methods that interact directly with the Redis instance to manipulate the quantity data:
add_quantityreduce_quantityreset_quantity
Imagine we write three test cases to validate each method of the Product class as follows:
# test_product.py
import pytest
from product import Product
from redis import Redis
redis = Redis()
class Test:
@pytest.fixture(autouse=True, scope="function")
def setup(self):
# Clean up test data from redis before running tests
redis.delete("product:1:quantity")
def test_add_quantity(self):
product = Product(1)
product.add_quantity(10)
assert product.quantity == 10
def test_reduce_quantity(self):
product = Product(1)
product.add_quantity(10)
product.reduce_quantity(5)
assert product.quantity == 5
def test_reset_quantity(self):
product = Product(1)
product.add_quantity(10)
product.reset_quantity()
assert product.quantity == 0
With the setup method to clean up any data in Redis before running tests, the same state can be provided to each test.
This way, the tests will consistently pass without incurring any flakiness if we run them sequentially.
However, if the tests are executed concurrently, there is a possibility of encountering flakiness due to potential race conditions or interference between the tests accessing the shared Redis instance.
You can actually observe non-deterministic outcomes at each execution if you run the tests in the example with pytest-xdist, a library that allows for concurrent execution of tests in Python.
One solution to prevent such flakiness due to concurrency within the test is to implement locks to ensure proper isolation of access to shared resources. For example:
import pytest
from product import Product
from redis import Redis
redis = Redis()
class Test:
@pytest.fixture(autouse=True, scope="function")
def setup(self):
# Clean up test data from redis before running tests
lock = redis.lock("redis_lock", timeout=5)
with lock:
redis.delete("product:1:quantity")
yield # Release the lock after the test (teardown)
def test_add_quantity(self):
product = Product(1)
product.add_quantity(10)
assert product.quantity == 10
def test_reduce_quantity(self):
product = Product(1)
product.add_quantity(10)
product.reduce_quantity(5)
assert product.quantity == 5
def test_reset_quantity(self):
product = Product(1)
product.add_quantity(10)
product.reset_quantity()
assert product.quantity == 0
With this modification, we can ensure that only one test or thread accesses the shared resource at a time, preventing race conditions and guaranteeing consistent results. While using locks adds overhead and may slow down test execution, it can at least reduce the possibility of flakiness caused by concurrent access to resources.
Heterogeneous test runners
The cause of flaky outcomes is not necessarily due to the way we write the code but also the way we organize test runners to run our tests in, for example, a continuous integration (CI) pipeline. So it may not be problematic if you run your tests only in your local environment or any other consistent environments. But it can happen in environments where multiple different test runners are used to execute tests.
Specifically, the problem with heterogeneous test runners arises from differences in their configurations, capacity, and dependencies. For instance, one test runner might lack some dependencies to run the tests. In this case, a test may pass on one runner but fail on another, leading to inconsistent results.
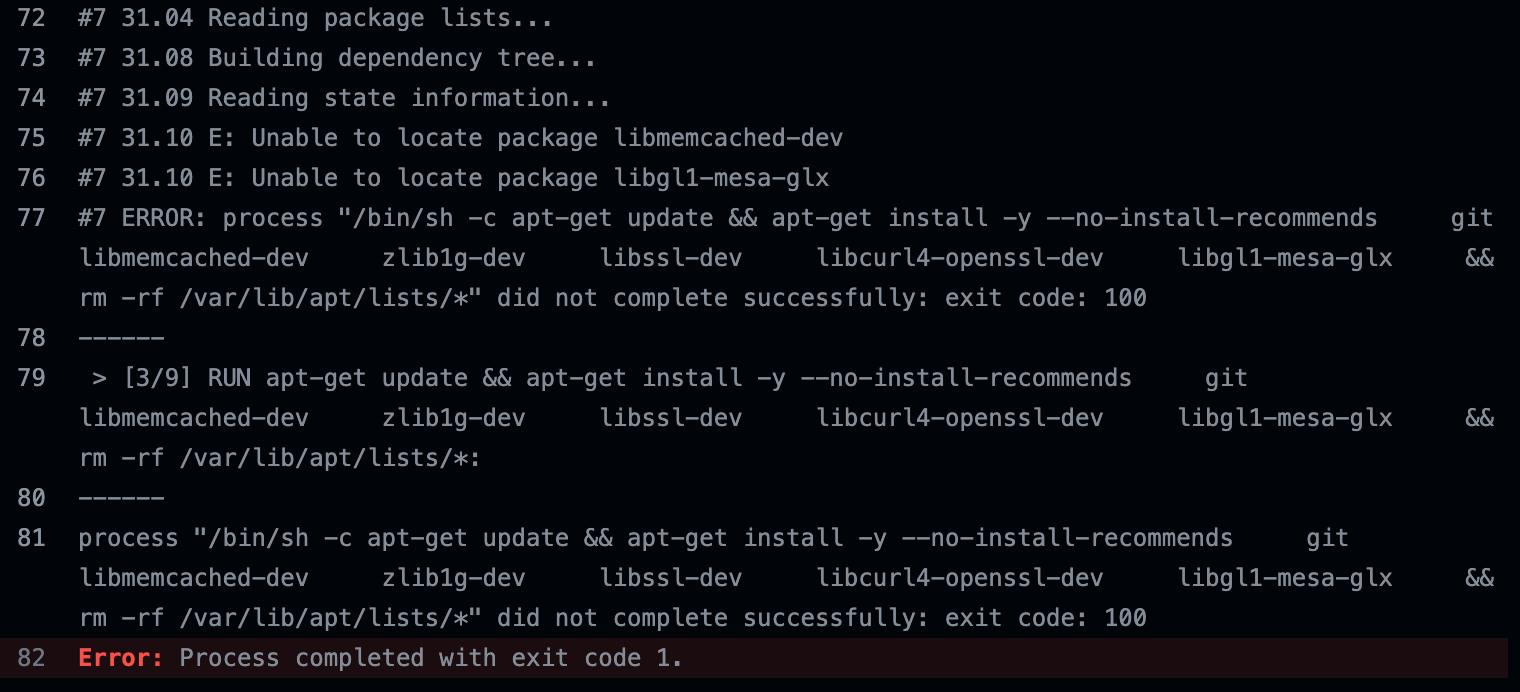 (A snippet of log from Github Actions.
We use self-hosted runners to run tests and encountered this issue from time to time.
Some of the test runners was missing a required dependency to run the test.)
(A snippet of log from Github Actions.
We use self-hosted runners to run tests and encountered this issue from time to time.
Some of the test runners was missing a required dependency to run the test.)
What’s more time-consuimg is that managing multiple test runners adds complexity to the testing infrastructure. Teams may struggle to synchronize configurations and updates across all environments. Additionally, troubleshooting flaky tests becomes more difficult when multiple runners are involved, as diagnosing the root cause requires understanding how each runner is configured and behaves.
To prevent such problem of having heterogeneous test runners, you can standardize your testing environment by adopting a unified approach. This involves ensuring consistency in all dependencies and system configurations across environments, which can lead to deterministic test results.
Note that it’s important to avoid writing flaky tests in the first place because, again, identifying the cause of these issues often leads to a significant reduction in productivity, as there is usually no straightforward way to track down the problem.
Brittle tests
Brittle tests are those that are sensitive to changes in the application, leading to frequent failures even when unrelated changes are made to the codebase. I am going explore two causes that can make tests brittle:
- over-specifying expected outcomes
- relying on extensive and complicated boilerplate
Let’s see how they might look and how to prevent them.
Over-specifying expected outcomes
The problem of over-specifying expected outcomes is that it tightly couples the test with the implementation details of the code, not the behavior.
Without further explanation, let’s look at the following code:
# product.py
from dataclasses import dataclass
from enum import Enum
@dataclass
class Product:
id: int
name: str
price: int
# Simulate product database
product_db = [
Product(id=1, name="Apple", price=10),
Product(id=2, name="Banana", price=20),
Product(id=3, name="Cherry", price=30),
]
class Sort(str, Enum):
price_asc = "price_asc"
price_desc = "price_desc"
def get_products(
id: int | None = None,
sort: Sort | None = None,
) -> list[Product]:
"""
Return a list of products based on the provided parameters.
"""
products = product_db
if id is not None:
products = [product for product in products if product.id == id]
if sort == Sort.price_asc:
products = sorted(products, key=lambda x: x.price)
elif sort == Sort.price_desc:
products = sorted(products, key=lambda x: x.price, reverse=True)
return products
The Product class three attributes - id, name and price.
And the get_products returns a list of Product objects based on the provided filter or sort parameters - id, sort.
Now look at test suite below:
from product import Product, Sort, get_products
class Test:
def test_get_products_with_no_parameters(self):
result = get_products()
assert result == [
Product(id=1, name="Apple", price=10),
Product(id=2, name="Banana", price=20),
Product(id=3, name="Cherry", price=30),
]
def test_get_products_with_id(self):
result = get_products(id=1)
assert result == [Product(id=1, name="Apple", price=10)]
def test_get_products_with_sort_price_asc(self):
result = get_products(sort=Sort.price_asc)
assert result == [
Product(id=1, name="Apple", price=10),
Product(id=2, name="Banana", price=20),
Product(id=3, name="Cherry", price=30),
]
def test_get_products_with_sort_price_desc(self):
result = get_products(sort=Sort.price_desc)
assert result == [
Product(id=3, name="Cherry", price=30),
Product(id=2, name="Banana", price=20),
Product(id=1, name="Apple", price=10),
]
The tests will always pass for now.
However, the tests will fail if an additional attribute is added to the product class for example:
# product.py
@dataclass
class Product:
id: int
name: str
price: int
quantity: int
# Simulate product database
product_db = [
Product(id=1, name="Apple", price=10, quantity=30),
Product(id=2, name="Banana", price=20, quantity=20),
Product(id=3, name="Cherry", price=30, quantity=10),
]
...
Here I added the quantity attribute to the Product class and updated the product database following the change.
If we run the tests above with pytest, the tests will break as follows:
...
============================================================ short test summary info ============================================================
FAILED test_product.py::test_get_products_with_id - TypeError: Product.__init__() missing 1 required positional argument: 'quantity'
FAILED test_product.py::test_get_products_with_sort_price_asc - TypeError: Product.__init__() missing 1 required positional argument: 'quantity'
FAILED test_product.py::test_get_products_with_sort_price_desc - TypeError: Product.__init__() missing 1 required positional argument: 'quantity'
========================================================== 4 failed, 1 passed in 0.02s ==========================================================
This is because the Product objects created in the test don’t include the quantity value.
In order to prevent such brittleness, we should aim to focus on testing the behavior rather than the implementation details.
Here’s a modified version to test the behavior, not the implementations:
from product import Sort, get_products, product_db
class Test:
def test_get_products_with_no_parameters(self):
result = get_products()
assert result == [
Product(id=1, name="Apple", price=10, quantity=30),
Product(id=2, name="Banana", price=20, quantity=20),
Product(id=3, name="Cherry", price=30, quantity=10),
]
def test_get_products_with_id(self):
result = get_products(id=1)
assert result[0].id == 1
def test_get_products_with_sort_price_asc(self):
result = get_products(sort=Sort.price_asc)
assert result == sorted(result, key=lambda x: x.price)
def test_get_products_with_sort_price_desc(self):
result = get_products(sort=Sort.price_desc)
assert result == sorted(result, key=lambda x: x.price, reverse=True)
Now the test becomes more resilient to change by focusing on the functionality of each parameter rather than the implementations.
It’s important to mention that the test_get_products_with_no_parameters still required modification after changes were made to the SUT.
This is because it’s intended to verify the outcome itself, as developers often need to test not only the behaviors but also the outcomes.
In other words, you can segregate the responsibility of verifying the outcome into one test case from the others that focus more on behaviors rather than the outcome.
Relying on extensive and complicated boilerplate
Extensive and complicated boilerplate can also make tests brittle.
First, let me illustrate how such tests can go break by unrelated changes. Look at the following example:
# customer.py
class Customer:
def __init__(self, name: str, phone: str):
self.name = name
self.phone = phone
# order.py
from customer import Customer
class OrderItem:
def __init__(self, id: int, name: str, price: float, quantity: int):
self.id = id
self.name = name
self.price = price
self.quantity = quantity
class Order:
def __init__(
self,
order_id: int,
custmer: Customer,
order_items: list[OrderItem],
):
self.order_id = order_id
self.customer = custmer
self.order_items = order_items
class OrderService:
def __init__(self):
self.orders = []
def add_order(self, order: Order):
self.orders.append(order)
def get_order_by_id(self, order_id: int) -> Order | None:
for order in self.orders:
if order.order_id == order_id:
return order
return None
def get_total_price(self) -> float:
total_price = 0
for order in self.orders:
for order_item in order.order_items:
total_price += order_item.price * order_item.quantity
return total_price
Here we have four classes OrderItem, Order, OrderService and Customer.
They clearly represent entities and services related to managing orders in the system.
An example of a test suite with extensive and complicated boilerplate would be as follows:
# test_order_service.py
import pytest
from customer import Customer
from order import Order, OrderItem, OrderService
class Test:
@pytest.fixture(autouse=True, scope="function")
def setup(self):
order_items = [
OrderItem(1, "Laptop", 1200, 1),
OrderItem(2, "Mouse", 10, 1),
OrderItem(3, "Monitor", 300, 1),
]
customer = Customer("Mickey", "01000000000")
order = Order(1, customer, order_items)
order_service = OrderService()
order_service.add_order(order)
self.order_service = order_service
def test_add_order(self):
order_service = self.order_service
customer = Customer("Bob", "555-5678")
order = Order(2, customer, [])
order_service.add_order(order)
assert order in order_service.orders
def test_get_order_by_id(self):
order_service = self.order_service
order = order_service.get_order_by_id(1)
assert order.order_id == 1
def test_get_total_price(self):
order_service = self.order_service
assert order_service.get_total_price() == 1510
At first glance, this test suite seems well-structured and organized.
The use of pytest.fixture to set up the order_service ensures that each test function operates on a consistent starting state, promoting test independence and reliability.
The tests themselves cover a range of scenarios, including adding orders, retrieving orders by ID, and calculating total prices.
But it has a vulnerability to brittleness in that it has extensive boilerplate in the setup method.
Suppose we add a new parameter email to the constructor method of the Customer class:
# customer.py
class Customer:
def __init__(self, name: str, phone: str, email: str):
self.name = name
self.phone = phone
self.email = email
This addition of the email parameter is unrelated to the existing functionality of the OrderService class and the test cases.
It doesn’t affect the logic of the methods being tested (add_order, get_order_by_id, get_total_price), but it does alter the structure of the Customer class.
As a result, the test suite will break because the Customer objects created in the test suite (setup method) do not include the email attribute:
================================ short test summary info ================================
ERROR test_order_service.py::Test::test_add_order - TypeError: Customer.__init__() missing 1 required positional argument: 'email'
ERROR test_order_service.py::Test::test_get_order_by_id - TypeError: Customer.__init__() missing 1 required positional argument: 'email'
ERROR test_order_service.py::Test::test_get_total_price - TypeError: Customer.__init__() missing 1 required positional argument: 'email'
=================================== 3 errors in 0.18s ===================================
One approach to resolve this problem is to use mocking:
# test_order_service.py
...
class Test:
@pytest.fixture(autouse=True, scope="function")
def setup(self):
order_items = [
OrderItem(1, "Laptop", 1200, 1),
OrderItem(2, "Mouse", 10, 1),
OrderItem(3, "Monitor", 300, 1),
]
customer = object() # Mock Customer
order = Order(1, customer, order_items)
order_service = OrderService()
order_service.add_order(order)
self.order_service = order_service
def test_add_order(self):
order_service = self.order_service
customer = object() # Mock Customer
order = Order(2, customer, [])
order_service.add_order(order)
assert order in order_service.orders
...
Now the tests become more focused on the functionality of the OrderServcie class and more resilient to change as they don’t depend on the implementation detail of the Customer class.
Do note that the misuse of mocks can also degrade the test quality. For instance, the overuse of mocks can make tests overly reliant on the mocked behavior, rather than accurately reflecting the behavior of the real system. To avoid these pitfalls, it’s important to use mocks appropriately with a clear understanding of their purpose and limitations.
Let’s change the context and look at another scenario where we may have to update the test.
This time, the Order class is changed to get a new parameter status:
...
class Order:
def __init__(
self,
order_id: int,
custmer: Customer,
order_items: list[OrderItem],
status: str,
):
self.order_id = order_id
self.customer = custmer
self.order_items = order_items
self.status = status
...
Adding status is seemingly unrelated to the existing functionality of the OrderService class and the test cases.
But the tests will break due to this change.
As for the question whether the change in this case should be counted as “unrelated” or “breaking”, I don’t have a clear answer.
If it’s breaking, we should go back to change the test.
If it’s unrelated, how would you address that?
One can try resolving the issue by providing a default value for the status argument in the Order class.
But that modification does not actually mitigate the brittleness inherent in the test.
(I am not necessarily saying it’s a bad idea. It’s rather reasonable considering that most orders would start with pending status.)
Maybe it’s both unrelated but also breaking.
With that being said, I want to point out that it’s quite difficult to avoid them entirely in the real world.
Here’s an excerpt from Software Engineering at Google:
The ideal test is unchanging: after it’s written, it never needs to change unless the requirements of the system under test change.
After all, striving for unchanging tests is the key idea to prevent brittle tests as much as possible.
Conclusion
The act of writing tests is desirable, but just writing them isn’t sufficient. Poorly written tests can become hard to maintain, resulting in increased costs and, in the worst-case scenario, leading to the neglect of test maintenance itself. And the larger the organization, the severer these issues can become. Therefore, it’s important to establish best practices and guidelines for writing resilient tests to prevent flaky tests and brittle tests in the future. I hope this post helps you understand the causes of flaky and brittle tests, enabling you to improve the quality of your tests.