
Processes
Definition
A process is an instance of an executing program. It is also referred to as a “task” or “job”.

In terms of “executing”, a process is an active entity. An application is a program that’s just stored on disk. This static entity becomes a process when it is launched and loaded in memory.
In terms of “instance”, a process represents the execution state of an active program. it is not necessarily running when it is waiting for the hardware resource to be allocated, or user input, and so forth.
A process is represented with its address space and its execution context in PCB.
Process Address Space
The process address space is the set of virtual addresses that point to the physical addresses in memory used by the process. In short, it’s a representation of a process in memory.
The layout of a process in memory is represented by the four sections:
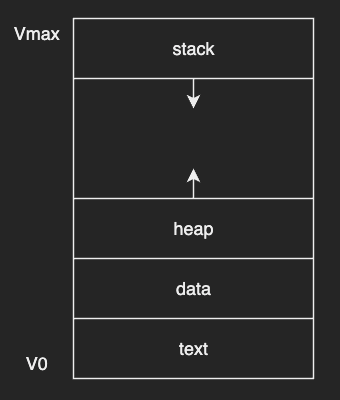
- text: the executable code, often referred to as an executable or binary
- data: global variables
- heap: memory that is dynamically allocated during program run time
- stack: temporary data storage when invoking functions
- function parameters
- return addresses
- local variables
The executable code is a set of instructions that the CPU can execute. This can be compiled from the human-readable application source code by a complier.
Both text and data are static and available when the process first loads. And unlike text and data sections whose sizes are fixed, the sizes of the stack and heap sections can grow and shrink dynamically.
The virtual (or logical) addresses, that range from V0 to Vmax in the figure above, don’t have to correspond to actual addresses in the physical memory.
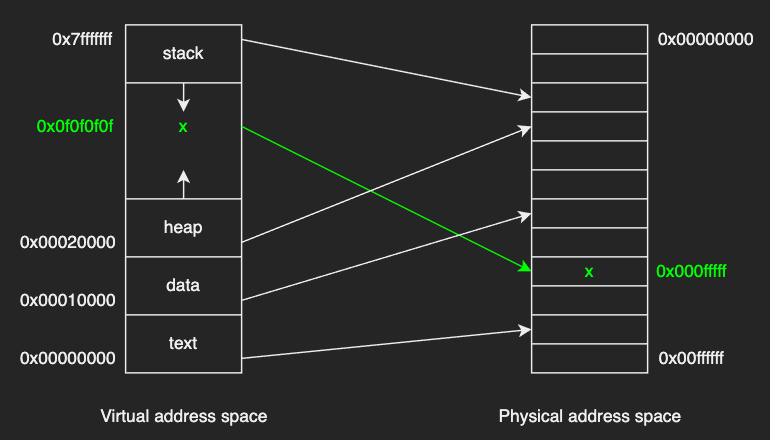
The figure above describes two main points of virtual addresses:
- The virtual address of a variable
xmay not be the same with the physical address of that variable in memory. Therefore, multiple processes can have the same virtual address space range, and the virtual address space for each process cannot be accessed by other processes unless it is shared. - The physical addresses for a process are noncontiguous. This way, the physical memory is completely independent of whatever the data layout of the process, thus allowing us to maintain physical memory management simple. In addition to that, a process can be allocated physical memory wherever such memory is available.
The OS creates the mapping between the virtual address and the physical address when requested to allocate some memory to the virtual address space, and stores it in a page table.
For example, a mapping model of the variable x in the page table would look something like this:
| virtual address | physical address |
|---|---|
| 0x0f0f0f0f | 0x000fffff |
This page-table entry is referenced whenever the process tries to access x.
Note that there may be portions of the address space that are not actually allocated as the physical memory may not be enough to store all of the states of the processes. To solve this physical limitation, some portions may be swapped temporarily on disk and are swapped back to memory whenever they are needed.
A takeaway here is that the OS must maintain the information about the process address space for each process.
Process Control Block
In most computer systems, the CPU executes multiple processes concurrently.
It means that the state of a process may change between running and idle a lot during its execution.
For the CPU can resume the process from where it was stopped (interrupted), the OS needs to store the information, such as which instruction the CPU must execute when the process is rescheduled to run. Such information is stored in a process control block.
A process control block (PCB) is a data structure to store all the information about a process. When a process is created, the OS creates a corresponding PCB and keeps it in an area of memory that is protected from normal process access.

Here are some of the data in a PCB:
- program counter: indicates the address of the next instruction to be executed for the process.
- process state: may be new, ready, running, waiting, and so on.
- CPU registers: include accumulators, index registers, stack pointers, and general-purpose registers, plus any condition-code informatoin.
- CPU-scheduling information: includes a process priority, pointers to scheduling queues, and any other scheduling parameters.
When the PCB is created, the program counter (PC) is set to point to the very first instruction in that process.
Some data are updated whenever the process state changes. For example, when an interrupt occurs, both the program counter and CPU registers must be saved. And when a process is allocated more memory by the OS, the memory limits information is updated.
Meanwhile, the CPU has a dedicated register to track the current program counter for the currently executing process and this register is automatically updated by the CPU on every new instruction. This way, the OS only needs to update the program counter in the PCB whenever that process is interrupted.
Context Switch
Context switch is the mechanism to switch the execution from the context of one process to the context of another process.
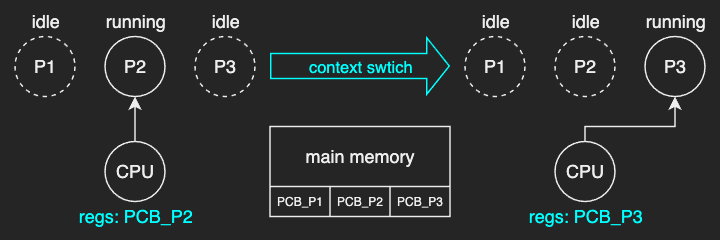
Look at the figure above for example.
The OS manages three processes (P1, P2, P3) and their corresponding PCBs (PCB_P1, PCB_P2, PCB_P3) are stored in memory.
When P2 is running, the CPU registers hold a value that correspond to the state of P2.
The OS switches the execution from P2 to P3 in the following order:
- The OS interrupts
P2, thenP2becomes idle. - Ths OS updates the
PCB_P2by saving all the state information ofP2into it. - The OS updates the CPU registers by reloading the state from
PCB_P3, thenP3becomes running.
Context switches are usually expensive for two reasons:
- direct costs: saving and loading registers and memory maps, updating PCB, etc.
- indirect cost: replacing CPU cache for the new data (cold cache)
The indirect costs are not directly caused by the context switch itself but eventually incur thereafter, because the data of P2 would not be in the cache the next time P2 is scheduled to execute.
For these reasons, optimizing context switches is one of the most important considerations when designing operating systems.
Process Lifecycle
A process can be in several states
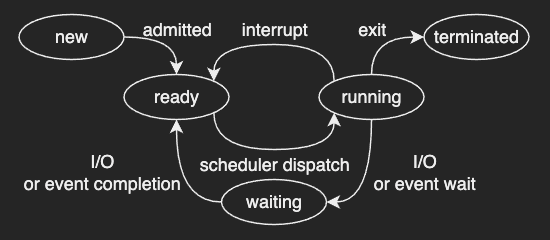
- new: The process is created.
- ready: The process is waiting to be assigned to a processor.
- running: Instructions are being executed.
- waiting: The process is waiting for some event to occur (such as an I/O completion like reading data from disk or reception of a signal like user input)
- terminated: The process has finished execution.
A new process is initially put in the ready state and waits until it is dispatched by the scheduler. And as soon as it is dispatched, the CPU starts executing it from the very first instruction that’s pointed by the program counter.
Process Creation
Two concepts to understand process creation:
- In traditional UNIX systems, the process named
initis the first process created when the system is booted, and is assigned a pid of 1. - A process may create several new processes during its execution. The creating process is called a parent process, and the new processes are called the children of that process.
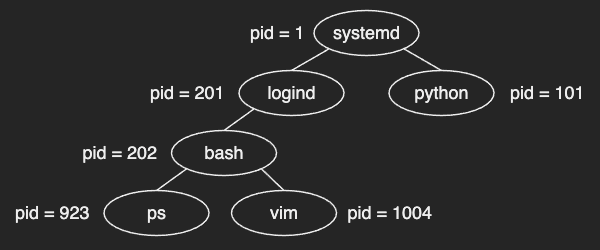
It means that all child processes are rooted from init process.
In recent distributions of Linux systems, it’s systemd instead of init.
And there are two mechanisms most operating systems use for process creation:
- fork
- copies the parent PCB into a new child PCB
- the child process continues execution at instruction after fork
- exec
- replace child image
- load a new program and start from the first instruction
In most UNIX systems, the ps or top command displays the current-running processes.
Process Scheduling
When the CPU is executing one process on it, there may be multiple processes waiting in a ready queue.
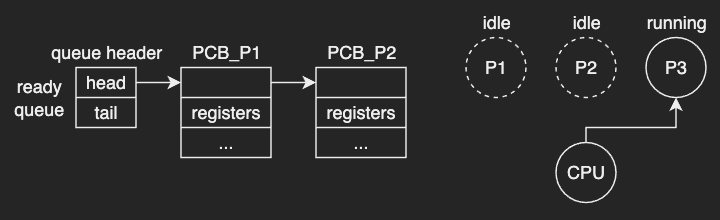
The queue is generally structured as a linked list as shown in the diagram above. A ready-queue points to the first PCB in the list, and each PCB points to the next PCB in the ready queue.
It is a CPU scheduler that determines which process in the ready queue will be dispatched to the CPU, and how long it should run for.
Here’s how the OS manages the CPU:
- preempt: The OS preempts to interrupt the executing process and save its current context.
- schedule: The OS runs the scheduling algorithm to choose which one of the processes in the ready queue should be run next.
- dispatch: The OS dispatches that process on to the CPU and switches into its context.
In this regard, the efficient scheduling algorithm and data structure to represent ready processes are important to consider when desiging operating systems.
For example, if the scheduling time is longer than the allocated processing time or time slice, most of CPU time would be spent on the scheduling work that is not really efficient.
I/O
A process can be placed in the ready queue in several ways.
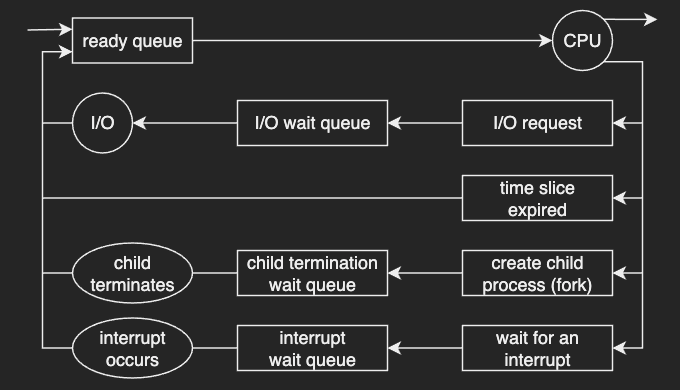
For example, the process could make an I/O request to access I/O devices such as network cards, disks, peripherals like keyboards. It is then placed in an I/O wait queue. When the I/O event is complete, the process is put back in the ready queue.
A process continues this cycle until it terminates, at which time it is removed from all queues and its PCB and resources are deallocated.
Inter Process Communication
Processes can be grouped into two types:
- Independent processes: do not share data with any other processes
- Cooperating processes: can affect or be affected by the other processes
Some reasons for allowing process cooperation:
- information sharing: Several applications may be interested in the common information.
- computation speedup: In multiprocessor systems, executing subtasks in parallel can achieve better throughput.
Inter-process communication (IPC) is a mechanism that allows cooperating processes to exchange data.
Two fundamental models of IPC:
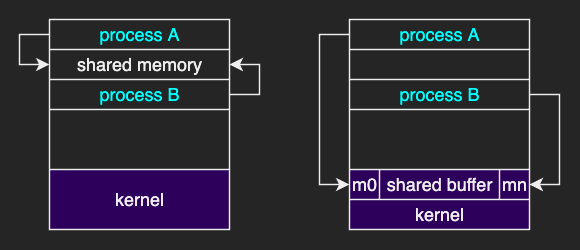
- message passing: data exchange through a communication channel
- shared memory: data exchange in a region of memory
In a message passing model, the OS establishes a communication channel, like shared buffer.
The cooperating processes can write/read a message from/to that buffer by using the OS-provided APIs like send and recv.
In general, this approach requires more time-consuming task of kernel intervention.
In a shared memory model, the OS establishes a shared channel and maps it into the address space of both processes. The cooperating processes can directly read and write from this address space with less overhead than the message passing model. However, developers would have to write code as it does not depend on the OS-provided functionalities.
And of course, both models need to be implemented in a way that every process is still guaranteed protection and isolation from one another.