
Thread Design Considerations
Thread Data Structures
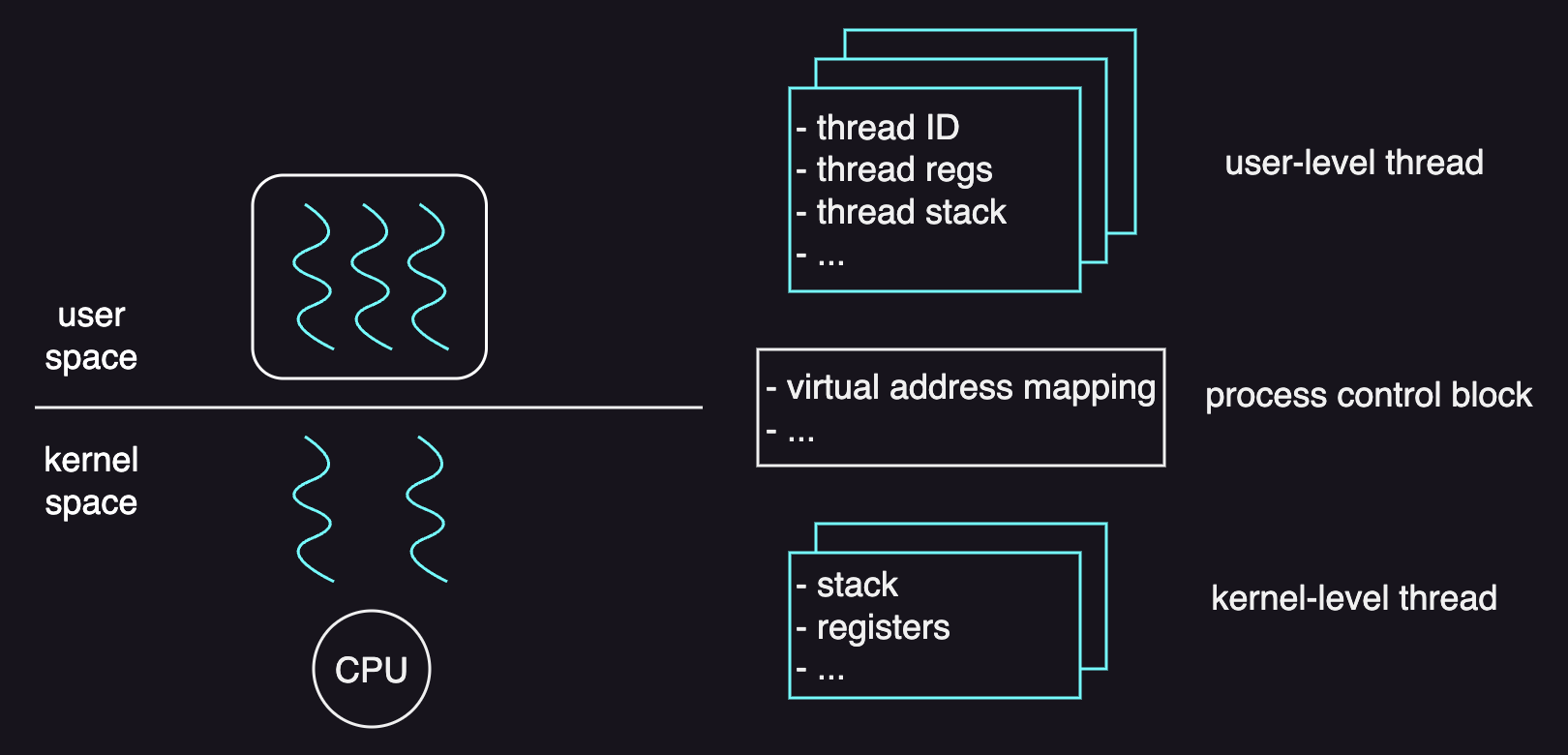
A user-level threading library has its own user-level thread data structure to represent threads in order to schedule and synchronize them. The thread data structure contains information such as:
- user-level thread ID
- user-level registers
- thread stack
On the other hand, the information that a kernel-level threading library needs to store in order to actually schedule threads onto a CPU is as follows:
- stack
- registers
- program counter
Because such information is stored in the process control block, if we wanted to create multiple kernel-level threads for a multithreaded process, the OS would have to replicate the entire process control block with all this information to represent different threads.
What the OS really does is that it only separates the information such as stack and registers from the entire PCB to represent the execution state of the kernel-level threads. In this way, the information such as virtual address mappings that can be shared among all of the kernel-level threads won’t have to be replicated.
With a multi-core system, the OS needs to have a data structure to represent the CPU and maintains a relationship between the CPU and the kernel-level threads. This CPU data structure has information such as:
- current thread
- list of kernel-level threads
And some information in a PCB is actually still specific to just one kernel-level thread:
- signals
- user-level registers
- system call arguments
Such information is stored in what’s called a lightweight process (LWP), which is an intermediate data structure between the user and kernel threads. This virtual processor-like data structure allows a user thread to map to a kernel thread.
As a result, it’s not just a single process control block, but multiple data structures that are more advantageous in:
- scalability
- overheads
- performance
- flexibility
Thread Management Interactions
In order for the operating system to efficiently manage threads, we need some interactions like system calls and special signals because both the user-level library and the kernel have no way to know each other’s activities.
When a process starts, the kernel gives a default number of kernel-level threads to that process.
It means that if we have a multithreaded process and its concurrency level is more than the default number of kernel-level threads, the process would have to request more kernel-level threads.
A system call for this operation is set_concurrency.
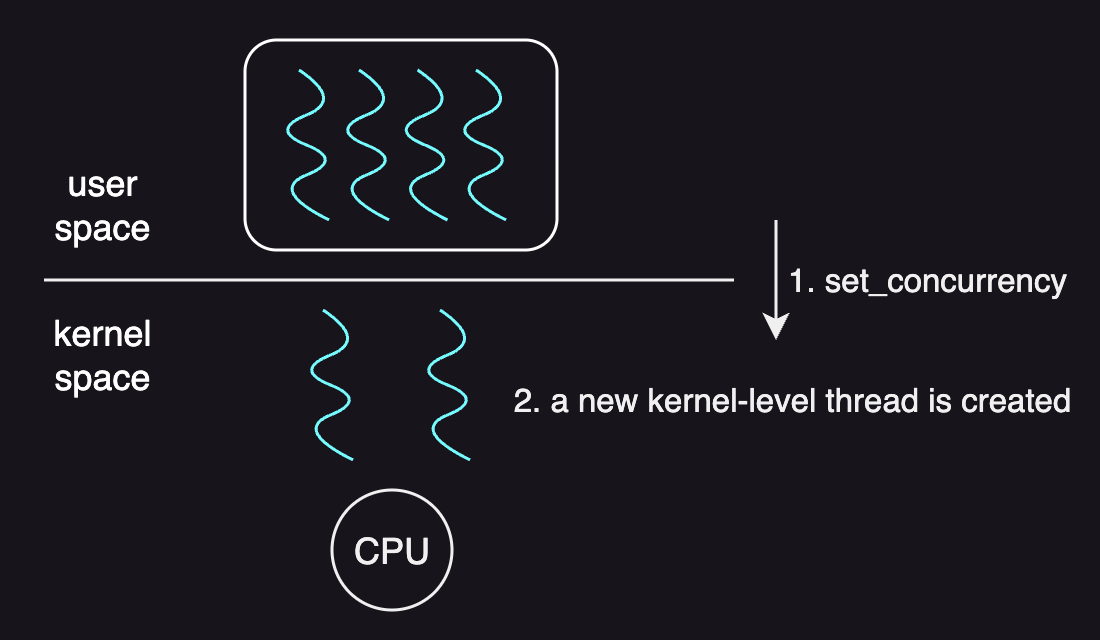
And suppose that a process has four user-level threads and only two of them are actually executing and the others are waiting on I/O at any given point of time. If the number of given kernel-level threads are two and their corresponding user-level threads block, the kernel-level threads are also blocked and the process as a whole is blocked too as there is no more underlying kernel-level threads for the other user-level threads to be mapped on.
In order to avoid such blocking issue, the kernel can notify the user-level thread library before it blocks the kernel-level threads so that the user-level library can find any executable user-level thread in its run queue and, in response, calls a system call to request more kernel-level threads or lightweight processes.
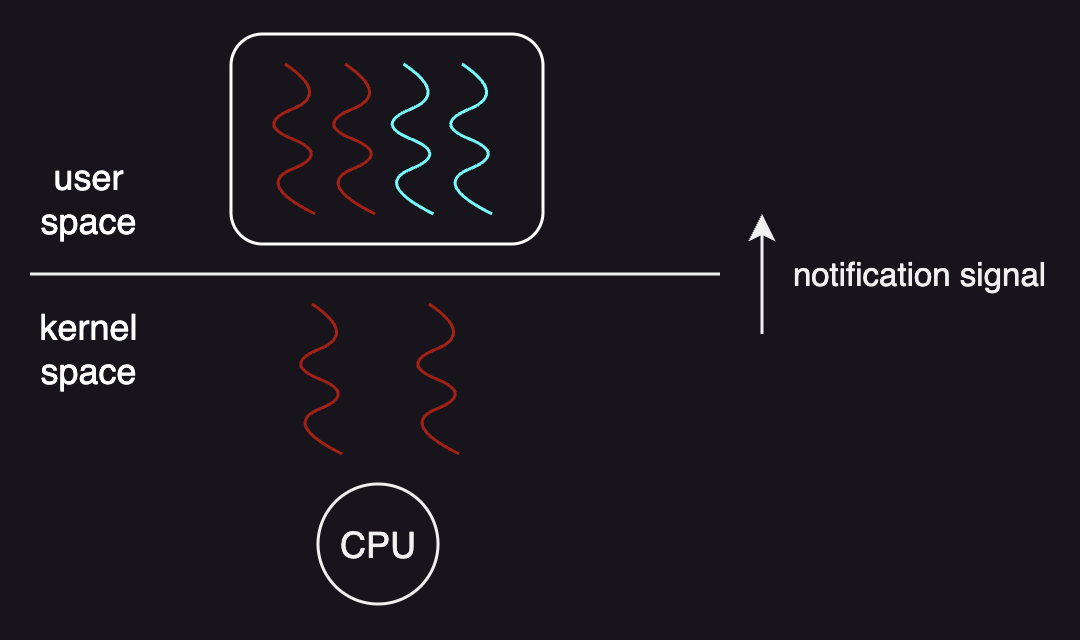
The other problem of a lack of visibility is that if the kernel preempts a kernel-level thread that is associated with a user-level thread that has a lock, the execution of this critical section is stopped and the other user-level threads that require that same lock in the same process will not be able to continue untill the preempted kernel-level thread is scheduled again and the critical section is completed so that the lock is released. The one-to-one multithreading model is the one that can address some of these issues.
And the user-level library scheduler can be triggered by:
- the user-level threads operations
- events or signals that come from either timer or kernel
In Linux, the minimum number of threads to boot the kernel is defined in a variable named MIN_THREADS which is 20.
And the maximum number of threads is defined in a variable named MAX_THREADS.
You can find these variables in fork.c file in a Linux kernel.
Interrupts and Signals
Interrupts are events generated externally by components other than the CPU, such as I/O devices, timers, and other CPUs. They are determined based on the physical platform and appear asynchronously.
On the other hand, signals are events triggered by the software that’s running on the CPU. They are determined based on the operating system and appear asynchronously or synchronously. For example, a synchronous signal is triggered if a process is trying to use unallocated memory.
Here are some analogies between interrups and signals:
- both have a unique ID depending on the hardware (interrupts) or on the OS (signals)
- both can be masked(ignored) and disabled (interrupt mask to a CPU, signal mask to a process)
- both trigger corresponding handler
Interrupts
In most modern devices, when a device wants to send an interrupt to the CPU, a message signal interrupter (MSI) is sent through the interconnect that connects that device to the CPU complex. The CPU complex can identify which one of the devices generated the interrupt based on the MSI message.
After the interrupt interrupts the execution of the thread that was executing on that CPU, if the interrupt is enabled only, an interrupt handler table is referenced based on the interrupt number. The interrupt handler table has information of the starting addresses of the interrupt handling routines. And then the program counter is set to the starting address of the corresponding interrupt handler.
| interrupt number | starting address |
|---|---|
| INT-1 | handler-1-start-addr |
| INT-2 | handler-1-start-addr |
| … | … |
| INT-N | handler-N-start-addr |
The supported interrupt numbers depend on the hardware and how they are handled is operating system specific.
Signals
Some examples of signals are:
- SIGSEGV (access to proteced memory)
- SIGFPE (divide by zero)
- SIGKILL (terminate)
For example, if a thread is trying to perform an illegal memory access, the OS generates a signal called SIGSEGV. This time, the OS refers to a signal handler table.
| signal number | starting address |
|---|---|
| SIGNAL-1 | handler-1-start-addr |
| SIGNAL-2 | handler-1-start-addr |
| … | … |
| SIGNAL-N | handler-N-start-addr |
The signal numbers are defined by the operating system, and how they are handled can be defined by the process. The fact that the process defines how a signal should be handled implies that the OS specifies the default actions such as:
- terminate
- ignore
- stop and continue
Masks
Both interrupts and signals can be disabled to avoid certain problems such as deadlock.
When an interrupt or a signal occurs, the program counter of the thread changes to point to the first instruction of the handler. On the other hand, the stack pointer will remain the same. The deadlock problem occurs if the handling code requires a mutex that is already acquired and not yet released by the thread that was interrupted. The handling routine will not complete as the interrupted thread has the mutex, and that thread will not release the mutex until the handling routine completes the execution.

Masks are used to avoid the deadlock problem by enabling or disabling whether the handling routine can execute. If the interrupt or signal is enabled, the handling routine is invoked and proceeded, otherwise, the interrupt or signal remains pending and will be handled later when the mask value changes.
For example, the thread would disable the interrupt before acquiring the mutex so that the interrupt will be disabled(ignored) and the deadlock is avoided.
Interrupts as threads
SunOS paper suggests that, to avoid the deadlock problem, a new thread is created to proceed the interrupt handling code. This new thread has its own context and stack so that it can remain blocked until the mutex is released and the original thread can be scheduled on to the CPU. After the original thread unlocks the mutex, the interrupt handling thread becomes able to execute.
One problem of the approach above is that the cost of creating a new thread is expensive. To address this problem, the OS can create new threads for interrupts dynamically, in which it creates a new thread if the handler code can block and it executes on the original thread’s stack if the handler code does not require the mutex. Otherwise, the kernel can optimize such dynamic decision cost by precreating and preinitializing certain number of threads for the interrupts.
As a result, performance is particularly important consideration when designing threads.