
Threads and Concurrency
A traditional process has a single execution context that can only execute at one CPU at a given point of time. If a process can have multiple execution contexts, it can take advantage of multi-core systems.
Definition
A thread is an execution context of a process. In other words, it is a basic unit of CPU utilization.
A traditional process with a single thread of control is called single-threaded process. And a process with multiple threads of control is called a multithreaded process.
The PCB structure of a multithreaded process is different than a single-threaded one.
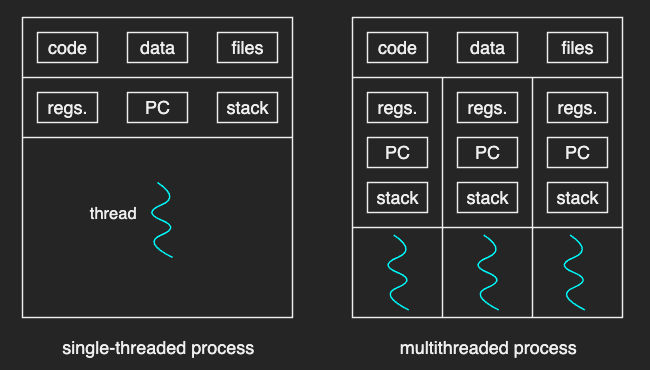
The multiple threads of a process share the same virtual address space. They share all the code, data, and files. However, each thread needs to have a different program counter, stack pointer, and thread-specific registers, as they may have different execution context.
Benefits
The main benefit of threads are performance.

Parallelization
For example, on a multicore system, multiple threads belonging to the process can execute the same code in parallel with a different subset of the input for each thread. In this way, the OS can process the input much faster than if only a single thread on a single CPU had to process the same input matrix.
Specialization
Multiple threads may execute completely different portions of the program as well. For example, a multithreaded web application can process different types of HTTP requests.
Moreover, if the thread repeatedly executes a smaller portion of the code, more of that state of that program will be actually present in the cache. (hot cache)
The same benefits can actually be achieved by multi-process implementation. However, that would require more memory as each process has to have their own address space. Moreover, interprocess communication is more costly than inter-thread communication.
A multithreaded process can also be useful on a single CPU.
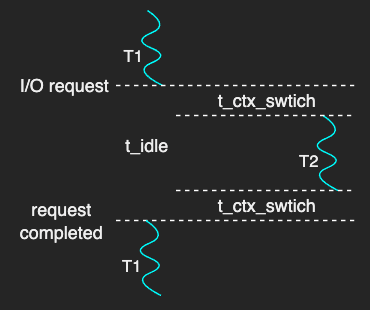
For instance, consider what happens when a thread makes an I/O request.
The thread has nothing to do but wait until it is responded.
If this idle time t_idle, is sufficiently longer than the time it takes to make two context switches t_ctx_switch, context switch to another thread can be more efficient.
In short, if t_idle > 2 * t_ctx_switch, multithreading is useful to hide latency that’s associated with I/O operations even in a single CPU.
And multithreading is beneficial to not only applications but also the OS kernel.
Thread Creation
The explanation here is based on An Introduction to Programming with Threads by Andrew D. Birrell. It does not necessarily correspond to other available threading systems or programming languages.
A thread type is a data structure that contains all information about a thread:
- thread ID
- program counter
- stack pointer
- registers
- stack
- additional attributes that can be used by the thread management systems
A thread is created by calling Fork with two parameters:
proc: the procedure to executeargs: the arguments for the procedure
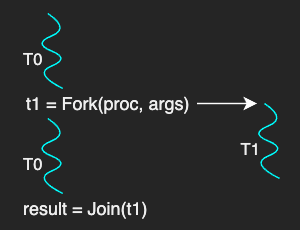
The Fork here is different from the Unix system call fork for process creation.
For example, when a thread T0 calls Fork(proc, args), a new thread type of T1 is created with its program counter pointing to the first instruction of the proc and the args available on its stack.
After the creation, both threads can execute concurrently as T0 will execute the next operation after Fork and T1 will also start executing its operation.
Optionally, T0 can call Join with a handler of T1, that is returned from Fork, to wait for T1 to terminate and retrieve the result.
Join is a blocking call so that T0 is blocked until T1 finishes.
When a thread is terminated, any allocated data for it is freed.
Concurrency Control & Coordination
Unlike processes, multiple threads can both legally perform access to the same physical memory because they share the same virtual-to-physical address mappings. This is problematic in that it could end up with some inconsistencies if multiple threads access the same data and modify it at the same time.
For example, consider two threads simultaneously incrementing the global integer variable x by 1:
read x;
increase x by 1;
write x;
| Thread 1 | Thread 2 | R/W | x |
|---|---|---|---|
| read x | <- | 0 | |
| read x | <- | 0 | |
| increase x | 0 | ||
| increase x | 0 | ||
| write x | -> | 1 | |
| write x | -> | 1 |
The final value is 1 instead of 2.
To safely coordinate among threads to prevent such data race problem, threads need some synchronization mechanisms such as:
- mutext: exclusive access to only one thread a time
- condition variable: specific condition before proceeding
Mutexes
A mutex is a mechanism that enables mutual exclusion among the execution of concurrent threads. In other words, it can be viewed as a resource scheduling mechanism. It is also referred to as a lock.
When a thread acquires a mutex, it has exclusive access to the shared resource. Other threads attempting to acquire the same mutex cannot proceed and may wait until that mutex is released. In other words, only one thread at a time can execute the critical section.
A mutex, as a data structure, needs to have some information about its status - whether locked or free.
The protected section of the program by the mutex, is called a critical section.
Lock(mutex) {
// critical section
} // unlock
Most common APIs provide different interfaces than Birrell’s one:
lock(mutex);
// critical section
unlock(m);
With this type of interface, the programmer must explicitly acquire the lock before entering a critical section, and unlock it thereafter so that other blocked threads can proceed.
The data race problem described in the example above can be handled like this:
lock(mutex);
read x;
increase x by 1;
write x;
unlock(m);
| Thread 1 | Thread 2 | R/W | x | acquire |
|---|---|---|---|---|
| lock(m) | 0 | success | ||
| read x | lock(m) | <- | 0 | failure |
| increase x | 0 | |||
| write x | -> | 1 | ||
| unlock(m) | 1 | |||
| lock(m) | 1 | success | ||
| read x | <- | 1 | ||
| increase x | 1 | |||
| write x | -> | 2 | ||
| release(m) | 2 |
As a result, the final value of x is 2, as expected.
One more thing to note is that Thread 2 needs to wait and retry lock acquisition after it failed to acquire the lock. It means that the programmer should consider this retry policy when using mutex.
Producer/Consumer Example
Suppose a case where multiple producer threads are inserting data to a queue (or buffer) with a maximum size, and a consumer thread is processing and clearing the data out from that queue when the the queue reaches its limit.
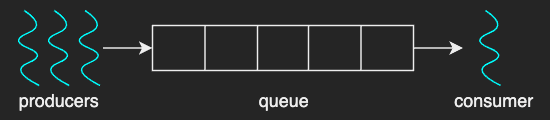
The risk of race conditions in this example can be eliminated with a proper mutex implementation:
// main
for i=0..3
producers[i] = fork(safe_insert, NULL)
consumer = fork(print_and_clear, my_queue)
// producers
Lock(m){
my_queue->push(thread_id)
}
// consumer
Lock(m){
if my_queue.full -> process; clear up the data;
else -> release lock and wait and retry
}
With a classic mutex, however, it wastes CPU resources due to the unnecessary busy-waiting:
- A consumer thread is always busy-waiting even if the queue is empty.
- Producer threads are always busy-waiting even if the queue is full.
This example is to allude that it would be more efficient if we can somehow signal the consumer thread when the queue is full so that it can process the data only when necessary.
Condition Variables
A conditional variable provides a mutex more complicated scheduling policies. It allows a thread to block until some event happens.
A condition variable API proposed by Birrell looks as follows:
TYPE Condition;
PROCEDURE Wait(m: Mutex, c: Condition);
PROCEDURE Signal(c: Condition);
PROCEDURE Broadcast(c: Condition);
A condition type may contain information such as mutex reference and a list of waiting threads.
Broadcast differs from Signal in that it notifies all threads waiting on a condition while Signal does only one thread.
The previous pseudocode example can be modified as follows:
// producers
Lock(m){
my_queue->push(thread_id);
if my_queue.full()
Signal(queue_full);
}
// consumer
Lock(m){
while (my_queue.not_full())
Wait(m, queue_full);
my_queue.process_and_remove_all();
}
The consumer locks the mutex and checks if the queue is not full.
If is not full, it then waits until a condition variable queue_full is signalled by other threads.
The producers on the other hand, it checks if the queue is full after pushing the data.
If it is full, it then signals queue_full.
Note that while statement is used to ensure that it checks the queue again after waking up from Wait.
Otherwise, it cannot guarantee that the queue is actually full before processing the data if, for example, there are multiple consumer threads.
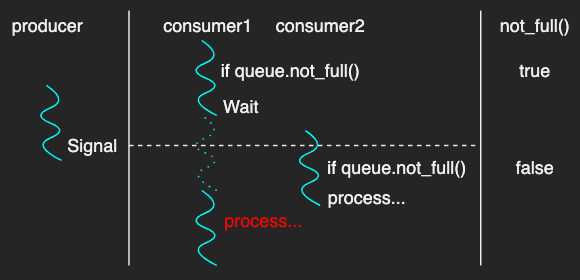
As described in the figure above, it is possible that another new consumer thread has acquired the mutex and has processed the queue as it had passed the if statement.
We can infer the semantics of Wait at this point:
- The first thing to do in
Waitis that the acquired mutex must to be automatically released so that the producers can acquire the mutex again. - The last thing to do in
Waitis that the mutex must to be automatically re-acquired for the consumer to continue processing with the mutex.
Readers-Writers problem
The reader-writers problems are examples of where multiple readers and writers are accessing the shared resource at the same time.
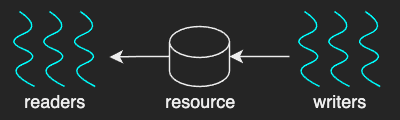
One naive approach to this problem would be to protect the resource with a mutex. This is too restrictive as only one thread at a time can access the resource although in practice multiple readers can read the resource at the same time.
This problem can be solved with a mutex, two condition variables and a proxy variable:
Mutex counter_mutex;
Condition read_phase, write_phase;
int resource_counter = 0;
// readers
Lock(counter_mutex){
while(resource_counter == -1)
Wait(counter_mutex, read_phase);
resource_counter++;
}
// read resource
Lock(counter_mutex){
resource_counter--;
if(readers == 0)
Signal(write_phase);
}
// writers
Lock(counter_mutex){
while(resource_counter != 0)
Wait(counter_mutex, write_phase);
resource_counter = -1;
}
// write resource
Lock(counter_mutex){
resource_counter = 0;
Broadcast(read_phase);
Signal(write_phase);
}
In this example, the actual resource, the real critical section, is not directly protected by the mutex.
Instead, before accessing the resource, both readers and writers have to acquire the mutex for a proxy variable, resource_counter, and update its value to represent the current state as follows:
- 0: free, either a writer or readers can access the resource
- n: n readers are reading the resource, any write must wait
-1: a writer is writing to the resource, any reader must wait
After the operation, they re-update the proxy variable and signal or broadcast to other waiting threads.
This implementation solves the problem in that multiple readers can read the resource at the same time.
Two more things to note:
- While multiple readers can read at the same time, readers that were waiting on the
read_phasemust still update theresource_counterone at a time. - The order of
BroadcastandSignalin writer code doesn’t really control the actual order as it’s the scheduler’s role.
Deadlock
A deadlock is a situation in which two or more threads are waiting on each other to release the lock.
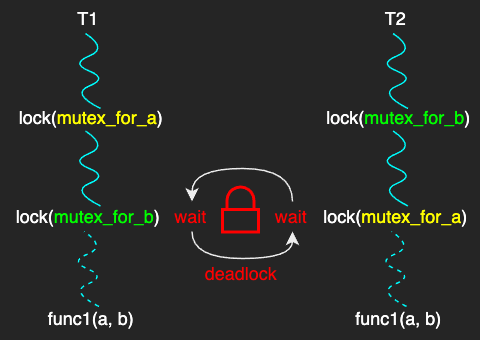
The most common solution is to maintain a lock order.
For instance, you can force every thread to get the mutex_for_a first and then get the mutext_for_b.
Deadlock prevention or detection/recovery mechanisms are expensive due to their overheads. In practice, it might be better to just let deadlocks happen when the program is more cost-effective to allow the deadlock than to implement such solutions.
Multithreading Models
Threads can be distinguished into two levels:
- user thread: a thread running in user mode
- kernel thread: a thread running in kernel mode
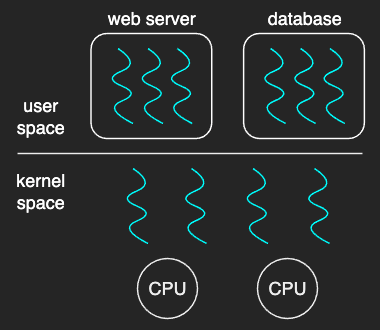
Kernel threads, or kernel-level threads, are supported and managed directly by the operating system, thus directly mapped onto the CPU. Most modern operating systems (such as Linux, Mac OS, Windows) provide kernel support for threads.
User threads, or user-level threads, are supported by the user-level library that is linked with the application and managed without kernel support. They are visible to the programmer and are unknown to the kernel, but they must be associated with a kernel thread to be executed, so that the OS level scheduler must schedule that kernel thread onto a CPU.
In that respect, the kernel-level threads look like virtual CPUs from the user-level threading library’s perspective.
There are three common models for establishing such a relationship.
One-to-One Model
The one-to-one model maps each user thread to a kernel thread. Thread management is done the by kernel.
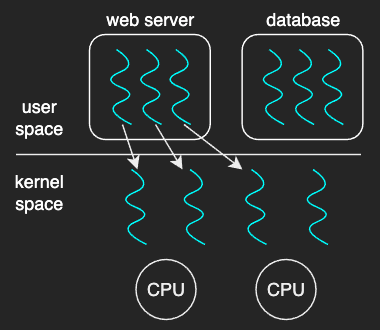
Pros:
- provide more concurrency than the many-to-one model.
- OS knows what user threads need in terms of synchronization, schedudling, blocking.
Cons:
- overheads - creating a user thread requires creating the corresponding kernel thread
- OS may have limits on policies or the number of threads
Most operating systems such as Linux and Windows implement this model.
Many-to-One Model
The many-to-one model maps many user threads to one kernel thread. Thread management is done by the user-level thread library.
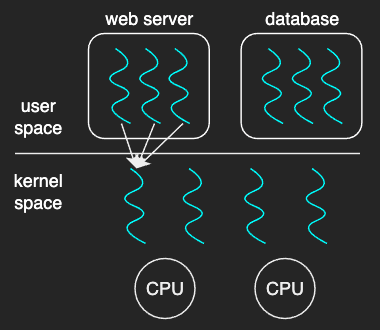
Pros:
- totally portable
- doesn’t depend on OS limits and policies
Cons:
- OS has no insights into application needs as it only sees one kernel thread
- the entire process will block if a thread makes a blocking system call
Very few systems use this model because of its inability to run multiple threads in parallel on multicore systems that are common nowadays.
Many-to-Many Model
The many-to-many model multiplexes many user threads to a smaller or equal number of kernel threads. It takes some advantages from both the one-to-one model and the many-to-one model.
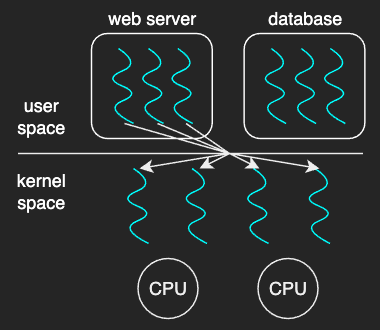
Pros:
- can have bound (a certain user thread mapped onto a kernel thread) or unbound threads
Cons:
- difficult to implement as it requires coordination between user and kernel level thread management in order to have some performance opportunities
This model is not used as much as the one-to-one model, because limiting the number of kernel threads has become less important with an increasing number of processing cores on most modern platforms.
Multithreading Patterns
There are some useful multithreading patterns for structuring multi-threaded applications.
Boss-Workers Pattern
In the boss-workers pattern, a boss thread assigns work to the worker threads, and the workers perform the entire task that’s assigned to them.
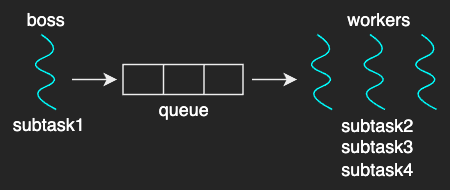
The throughput of the system is limited by the boss thread’s perforamnce (througput = 1 / boss_time_per_order). In other words, the boss must be kept efficient to gain better throughput.
In that sense, a common approach to this pattern is setting up a queue between the boss and the workers, as described in the figure above. Although it requires some synchronization to the shared queue, it results in better throughput by decoupling the boss from the responsibility to keep track of what each worker is doing to distribute the task.
Creating new workers for more tasks in a queue is also an expensive operation. Typically, a pool of threads is used to reduce such overhead. And the size of the pool can be static or dynamically adjusted depending on what’s best for the situation.
Pros:
- simplicity
Cons:
- thread pool management
- locality
Do note that the workers do not necessarily have to do the same subtasks. A group of workers can be specialized for certan tasks to achieve better performance with better locality.
Pipeline Pattern
The pipeline pattern divides the overall task into subtasks, and assigns each subtask to a thread.
The throughput of this model depends on the longest stage in the pipeline. In other words, the performance would be best if every stage takes about the same amount of time.
Pros:
- specialization and locality: when threads perform a more specialized task, it’s more likely that the state they require for their processing is present in the processor cache.
Cons:
- balancing and synchronization overheads
Comparing two patterns
Consider a multi-threaded application performs tasks with 6 threads:
- in the boss-workers pattern, a worker processes a task in 120ms
- in the pipeline pattern, each stage takes 20ms
- the overheads due to synchronization or data communication are ignored in this example
The formulas:
- boss-worker: time_to_finish_1_order * ceiling (num_orders / num_concurrent_threads)
- pipeline: time_to_finish_first_order + (remaining_orders * time_to_finish_last_stage)
To complete 1 task:
- boss-workers: 120 * ceiling(1/5) = 120ms
- pipeline: 120 + (0 * 20) = 120ms
To complete 10 tasks:
- boss-workers: 120 * ceiling(10/5) = 240ms
- pipeline: 120 + (9 * 20) = 300ms
To complete 11 tasks:
- boss-workers: 120 * ceiling(11/5) = 360ms
- pipeline: 120 + (10 * 20) = 320ms
The result clearly shows that not one pattern is always better than another one.
As an application developer
Designing multithreaded applications must be done carefully to avoid mistakes of missing locking or unlocking a resource, or using wrong mutexes or conditional variables. It also takes a lot to consider in terms of performance, overheads, deadlocks, and so on. To avoid such problems and achieve better performance, do analyze your code and try comparing the different approaches.